Nel precedente articolo abbiamo parlato del funzionamento del Producer/Consumer Pattern, come si comportano le code e quali vantaggi possiamo trarre dal loro utilizzo.
In questo articolo volevo confrontare Queue e Notifier, descrivendo il loro utilizzo e le differenze principali.
I Notificatori, come le code, sono utilizzati generalmente per comunicare (passare i dati) attraverso due Loop paralleli oppure tra diversi VI in esecuzione sulla stessa macchina.
Per capire al meglio la similitudine, è utile dare un’ occhiata alle principali funzioni:

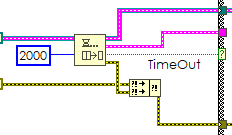
| Obtain Notifier: Crea un riferimento a una Notifica,bisogna specificare il tipo di dato. | Obtain Queue: Crea un riferimento a una Coda,bisogna specificare il tipo di dato. |
| Send Notification: Invia un messaggio a tutte le funzioni di notifica in attesa. | Enqueue: Accoda un elemento per la funzione (una sola) Dequeue |
| Wait on Notification: Attende finchè non riceve un messaggio, la funzione riceverà solo l’ultimo messaggio. | Dequeue Element: Attende che ci sia almeno un elemento nella coda e li “scoda” ovvero li rimuove presentandoli in uscita. |
| Release Notifier: Rilascia il riferimento alla notifica, distruggendola. | Release Queue: Rilascia il riferimento alla notifica, distruggendola. |
Come si può notare le funzioni di Coda e quelle di Notifica si assomigliano molto, ma presentando differenze in come i dati vengono trattati.
Infatti possiamo dire che i Notifier non hanno memoria, solo l’ultimo dato inserito è disponibile, ma può avere molti lettori del dato in quanto la lettura non elimina il dato.
Le code invece hanno memoria (buffer FIFO o LIFO) ma possono avere un solo lettore che ne cancella il dato.
In pratica nel notifier il dato viene sostituito dallo scrittore, nelle code viene rimosso dal lettore che lo processa.
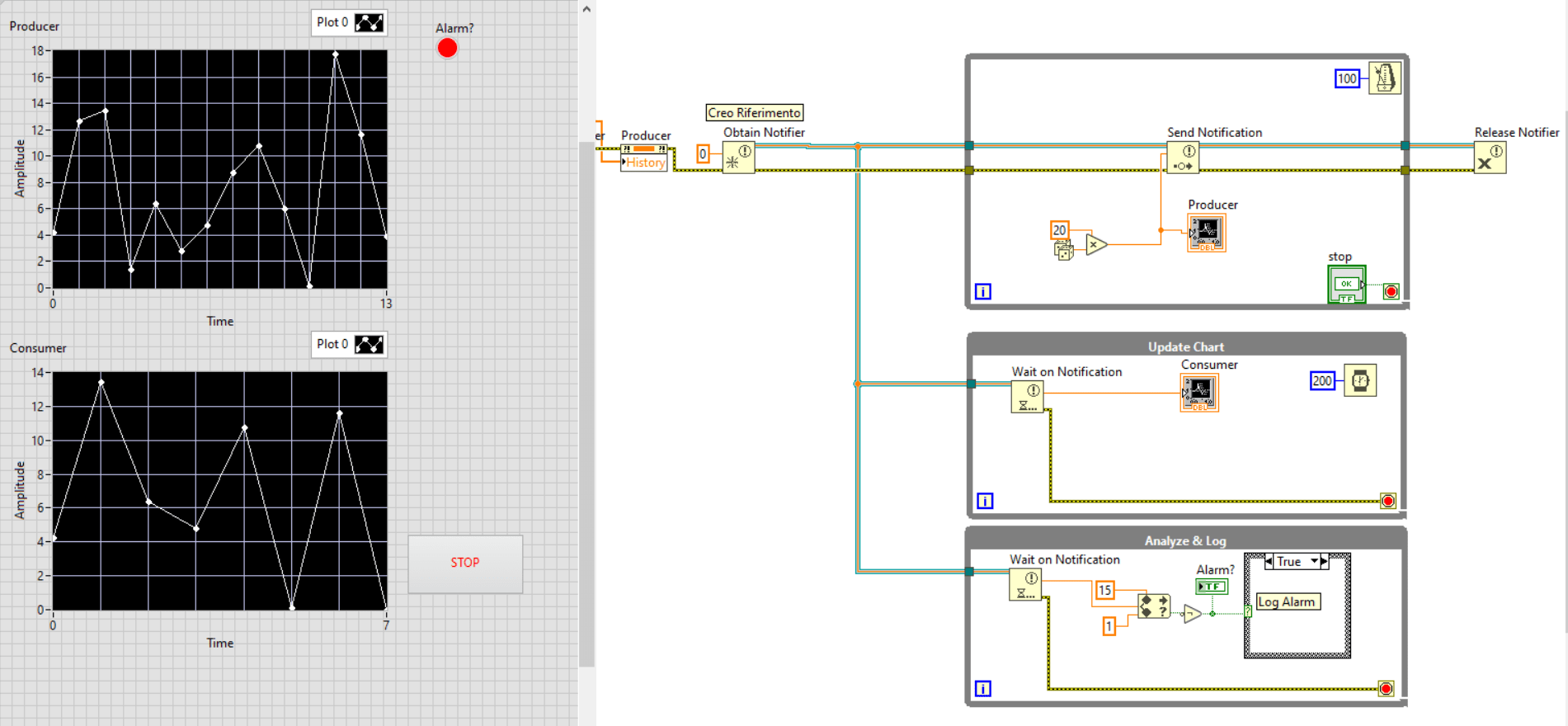
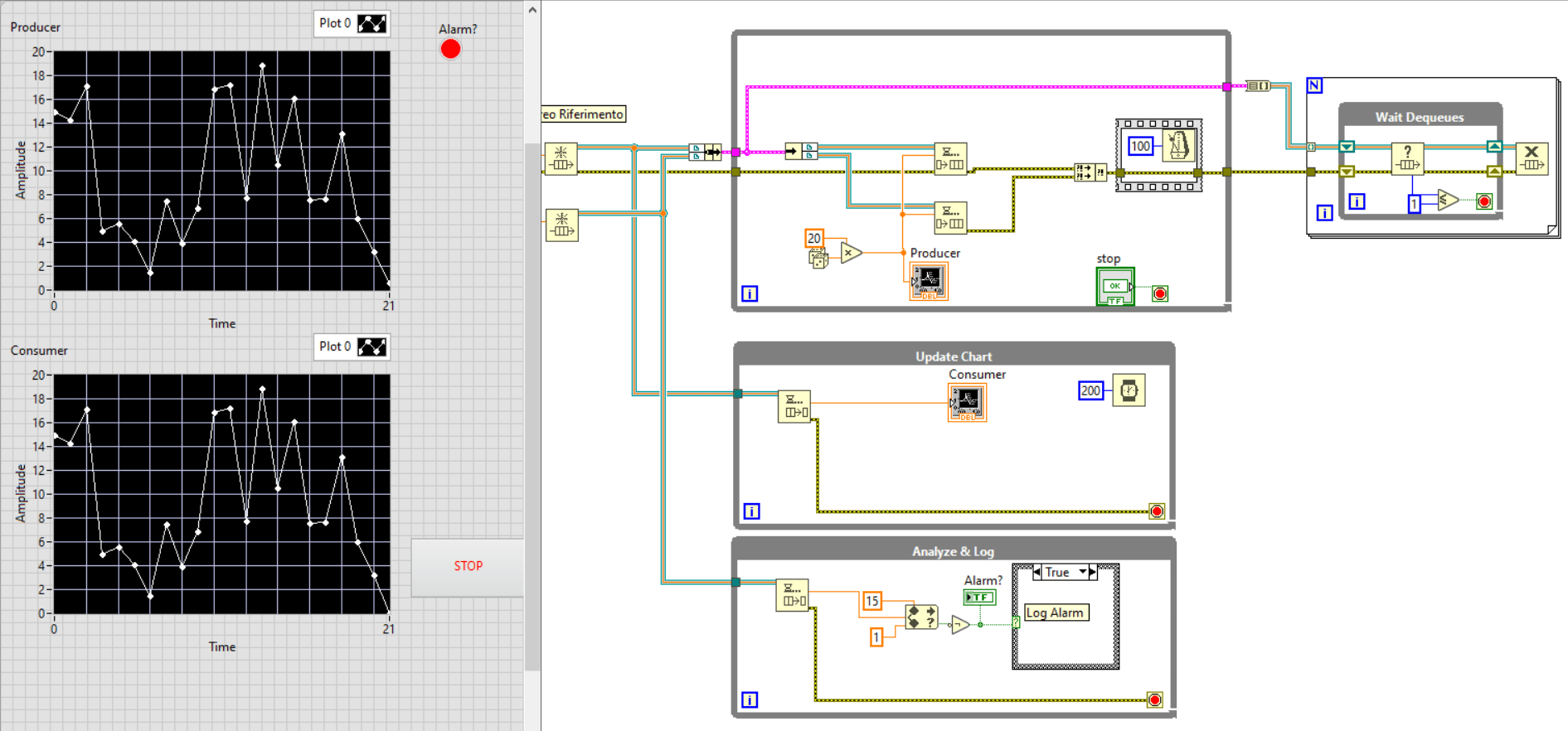
Il primo processo, aggiorna il notifier ogni 200ms.
Il secondo processo lo legge non appena è disponibile, ma prima di iterare nuovamente ha una funzione che lo rallenta di 200ms (simulato a titolo di esempio con il wait), per cui perderà informazioni.
Il terzo processo come per il secondo ha il dato ultimo aggiornato, ma probabilmente se la funzione di log impiega tempo perderà informazioni.
Se non ci interessa la perdita di informazioni, perchè magari il processo è molto lento.
Questo modello ci ha permesso di parallelizzare tre processi Acquisizione, Visualizzazione e Analisi/Log, notare che ci siano due processi in attesa dello stesso notifier.
Se invece abbiamo necessità di elaborare tutti i dati generati , dobbiamo ricorrere alle code, ricordando che in questo caso abbiamo solo un ricevitore, per cui per avere due consumer indipendenti si devono utilizzare due code.
In questo caso si deve notare l’effetto di avere i grafici alla fine dell’esecuzione identici ovvero tutti i dati generati sono stati processati, anche se i consumer hanno diversi tempi di iterazione..
Notare invece che abbiamo dovuto creare due code, una per ogni consumer.
Nota sul VI: Il For in uscita contiene un Get Queue Status, per attendere che i consumer abbiano scodato tutti gli elementi prima di terminali con destroy queue.
Un vantaggio comune è che i consumer non hanno necessità di temporizzazione (a meno che non sia necessaria per necessità di visualizzazione o altro) e non hanno polling, ottimizzando la percentuale di CPU richiesta.
Ovviamente le funzioni di notifica, come le Code, possono essere usate in combinazione con gli eventi, ciò permette appunto di sviluppare applicazioni con un interfaccia utente.
In conclusione si può quindi dire:
La funzione Notifier è adatta per comunicazioni dove è accettabile la perdita di dati beneficiando della relazione “Uno a Molti“, dove N ascoltatori processano un codice fino a quando questo non è sovrascritto.
La funzione Queue, al contrario, è adatta per comunicazioni senza perdita di dati con relazioni di tipo ” Molti a Uno“, dove multipli processi vengono memorizzati all’ interno del buffer di coda ed eseguiti da una singola funzione, senza perdità di dati.